


会议
- 会议
- 资讯
重磅!华南理工大学团队提出自然语言微调技术(NLFT),助力大模型普及!
更新时间:2025-02-13

随着国家推动人工智能创新与应用、实现自主可控技术突破和产业转型升级的趋势、要求和数字经济的迅猛发展,人工智能大语言模型(LLM)被视为新一代信息工业革命的基础设施和新型生产力,能够为各行业的智能化进程注入强大动力。
近日,由华南理工大学计算机科学与工程学院长聘正教授、华中科技大学嵌入式与普适计算原实验室主任陈敏教授主导,联合了华中科技大学、琶洲实验室与华南理工大学的科研团队,在自然语言大模型小样本微调研究领域取得重要突破。论文“Natural Language Fine-Tuning”提出了一种简单、低成本且极大提高准确率的全新方案——自然语言微调(NLFT)。

论文链接:https://arxiv.org/abs/2412.20382
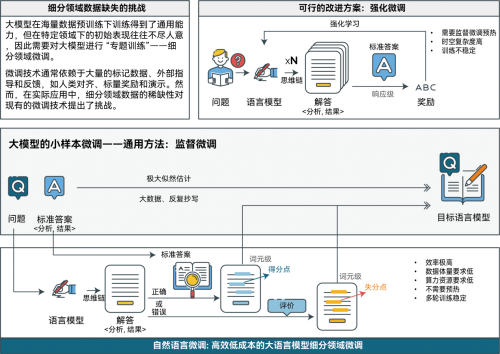
科研团队利用AI领域攻关取得的成果,提出了自然语言微调技术(NLFT)。这一技术通过利用少量随机训练数据,经过少数几轮训练,在较短时间和有限显存条件下,能够显著提升基础大语言模型(LLM)的准确率。与字节跳动提出的强化微调(ReFT)相比,NLFT在时间和空间复杂度上都有明显优化,并且仍具有较大的提升潜力。该技术为突破传统微调方法中对大量数据和高算力资源的依赖提供了新的可能。NLFT是科研团队自主研发的国内具有独特优势的算法。
从宏观层面看,NLFT可以视为对传统监督微调(SFT)技术的一种优化。与强化微调(ReFT)不同,NLFT通过对token级别的细粒度优化,能够有效替代传统的SFT过程,无需像ReFT那样进行多轮预热,从而省去了大模型的预热环节(warm-up),支持冷启动(cold-start)。具体而言,科研团队利用目标模型本身作为自然语言评价器,发挥其对语言的深刻理解能力,精准标注出答题过程中的得分点与失分点。这一过程不依赖任何外部指导,充分展示了NLFT在领域微调中的高效性与可操作性。
自然语言微调(NLFT)方案以简洁的设计、较低的成本投入,以及准确率提升中的显著成效,大幅降低了大语言模型(LLM)的准入门槛,摆脱了以往对海量数据和高算力资源的依赖,使得LLM更加平民化,使用该技术在单张消费级显卡RTX 4090上跑通的8b微调大模型,可以在使用极少专家数据的前提下获得成倍的性能提升,为LLMs的大规模训练和部署提供了新的可能性。提升了其在特定细分领域的能力,减少了传统微调方法需要借助大量领域数据所带来的高昂成本。
自然语言微调技术的核心理念
研究团队正在积极开展领域微调的泛化研究,探索其在多个应用领域的潜力。例如,在医学诊断中,团队利用少量有标签数据,并结合思维链与比对生成的内容与标签,实现了词元精准标注和推理优化。除此之外,NLFT技术在程序设计、自然语言推理和复杂问答系统等领域也具有广泛应用前景,预计将为细粒度模型微调提供重要支持,推动更多实际应用的落地。



















-
.png)
 顾问老师
顾问老师扫码添加顾问老师

-
.png)
 微信客服
微信客服扫码添加平台客服

-
.png)
 客服电话
客服电话电话:13922151049
-
.png)
 公众号
公众号关注AEIC公众号查看更多资讯

